Qwen-VL 论文阅读
Qwen 中文名是通义千问,由阿里,对应的多模态版本是 Qwen-VL。Qwen 能够根据用户的 prompts, 完成各种视觉任务。相比于其他任务,该模型在 grounding,文本阅读,面向文本问题问答和细粒度对话等方面具有优势。这个模型支持交错图文的输入。
方法
模型基于Qwen,由三部分组成:
视觉编码器,使用openclip的ViT-bigG,训练和推理过程中以步长14切分图像patch;
大语言模型,使用 Qwen-7B 模型;
位置感知视觉-语言适配器(Position-aware visual-language adapter),用来缓解长序列图像带来的效率问题。这一部分包括了一层随机初始化的交叉注意模块,这个模块使用一组可训练的embeddings作为查询向量,将视觉编码器的特征作为key来进行交叉注意的操作。
图像输入:视觉编码器和适配器对图像提取固定长度的特征序列,为了区分图像和文本,在这些特征序列的开头和结尾添加<img>和</img>标记,用以表示图像内容的开始和结束。
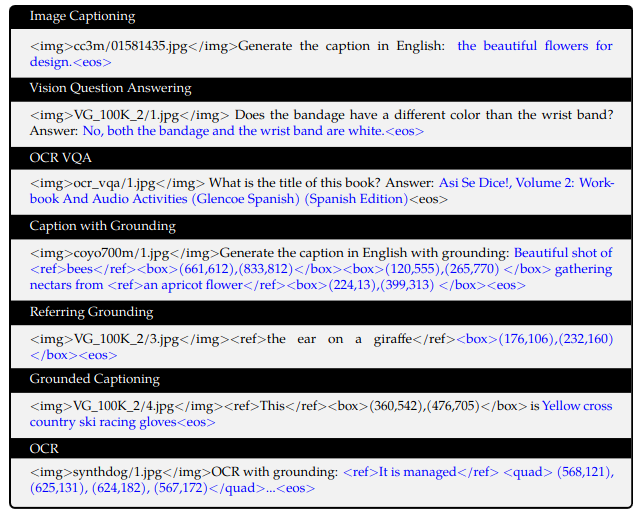
Bounding box:为让模型支持细粒度的视觉理解能力,用具有区域的描述、问题和检测这种类型的数据训练Qwen。细粒度视觉理解需要准确理解并生成图像中区域的描述,而不是整体的描述。
数据集构造如图里所示的那样,模型通过特定的标记来理解用户输入的bb,也通过特定的标记生成bb(蓝色部分对应有ground truth的输出,黑色部分是前缀序列)
训练
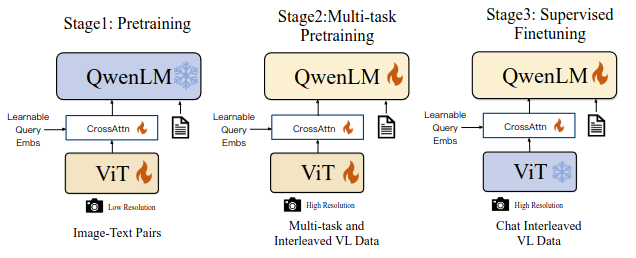
文章中提到模型的训练分为三个步骤:
预训练:用大规模从网络抓取的弱标签图像-文本数据来训练网络;这一阶段固定LLM,这一阶段图像的输入大小被统一为224x224;
多任务训练:这一阶段用高质量的和细粒度的视觉-文本数据来训练网络,这一阶段对网络所有参数进行调整,这个阶段在7个任务上对模型进行训练,视觉编码器的输入分辨率从224x224提升到448x448,作者在消融实验中发现,使用全局注意力机制在训练阶段不比window 注意力机制慢,但能够显著提升模型能力,所以最终采用 Vanilla Attention提取图像特征。

Fine-tune:这一阶段使用instruction fine-tune提升模型对话能力,这一部分数据主要来自于LLM生成的数据或者图像caption数据,缺少图像目标定位和多图像对话数据,这一部分主要靠手动做一些标注、模型生成或者是通过策略拼接组合一些数据的方式来造instrunction tune数据集。训练过程中混合了多模态和纯文本数据以确保模型语言能力。
实验
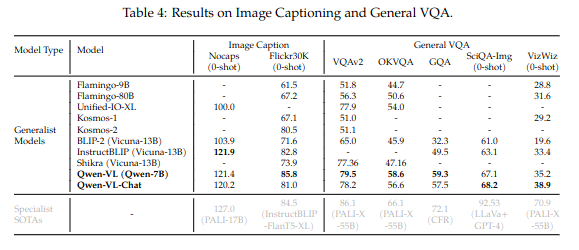
模型在image caption任务和通用的VQA任务里表现出色
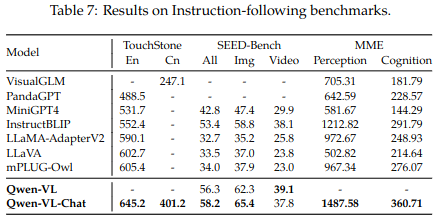
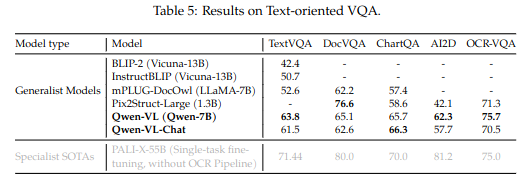
在面向文本的VQA任务里表现也同样出色:
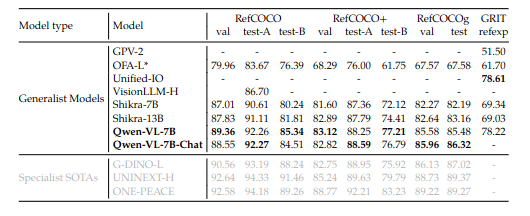
Refer Expression 能力,这个能力要求模型在给定模型描述的情况下定位目标。
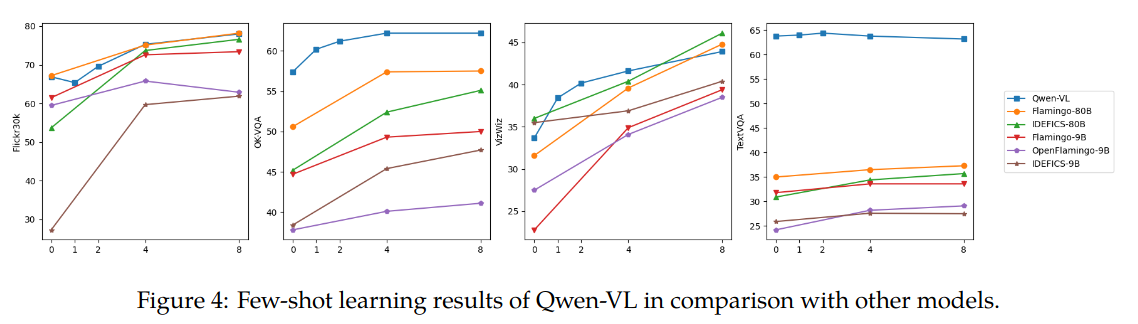
Few-shot:
instruction following 能力,评估真实世界下模型同用户交互能力: